括弧でくくる: Sample 4: テイラー展開(FORTRAN)
言語の変更:
C版
■ 概要
テイラー展開とは三角関数や指数関数のような複雑な関数を多項式に近似させる手段です。三角関数や指数関数はほとんどのプログラム言語で組み込み関数として用意されているので、実際のプログラミングではあまり使われないかもしれません。しかしベッセル関数などの、より複雑な関数となると、組み込み関数としてほとんどの言語にないので、自力でそのテイラー展開を求めてコーディングしなければなりません。
このサンプルでは式(1)に示すsin(x)のテイラー展開を例にして挙げます。べき数は掛け算の繰り返しなので、式(1)のままで計算すると掛け算の回数は3+5+7+9=24です。括弧を駆使すれば、掛け算の回数が半分以下に減らせます。
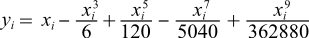 ... 式(1)
... 式(1)
下の「回答例」ボタンをクリックすれば、式(2)に回答例が表示されます。興味がある方はクリックする前にぜひ考えてみてください。
式(2)では掛け算が8回まで減ります。なお、ダミー変数を積極的に使用で紹介したようにxi2をダミー変数にしておけば掛け算の回数をさらに減らせます。
Code 1は式(1)によってコーディングしたものです。Code 2は式(2)によってコーディングしたものです。配列xとyのサイズnは10,000とします。計算時間が非常に短いので、より正確な計算時間を得るためにこの計算は100,000回まわします。
■ ソースコード
| ◆ Code 1 | ◆ Code 2 |
|
|
■ 計算時間の測定結果
Code 1とCode 2の計算時間の測定結果を表1に示します。ここではそれぞれのコードを5回実行して、平均とCode 1とCode 2との計算時間の比率も表示します。
| 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 平均 | 倍率 | |
|---|---|---|---|---|---|---|---|
| Code 1 | 5.97 | 5.85 | 5.73 | 5.73 | 5.77 | 5.81 | 1.57 |
| Code 2 | 3.63 | 3.85 | 3.71 | 3.65 | 3.67 | 3.70 | - |
■ 考察
Code 1はCode 2に比べて掛け算が2回以上多いため、計算時間も1.57倍遅いという結果が得ました。
